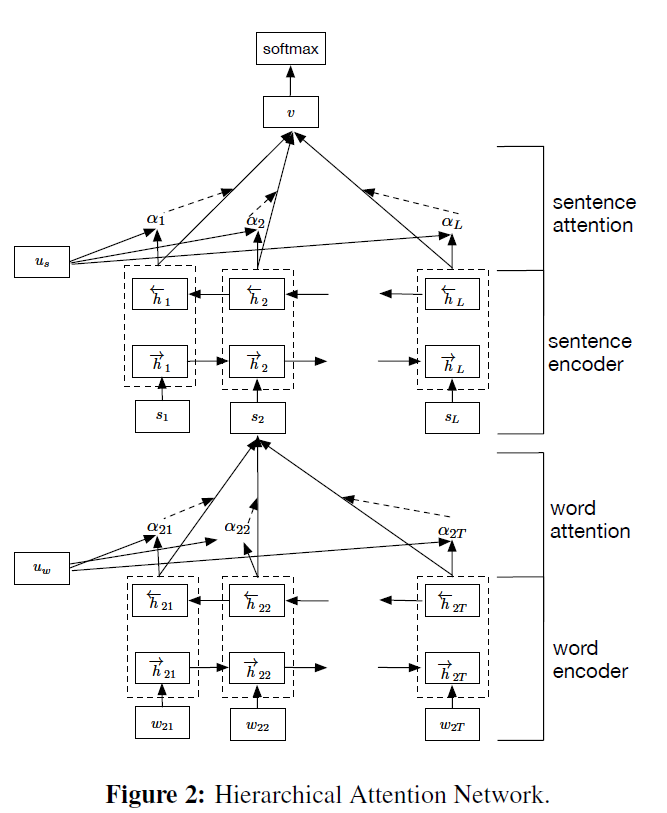
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| import torch.nn.functional as F
from torch import nn
class SelfAttention(nn.Module):
def __init__(self, input_size, hidden_size):
super(SelfAttention, self).__init__()
self.W = nn.Linear(input_size, hidden_size, True)
self.u = nn.Linear(hidden_size, 1)
def forward(self, x):
u = torch.tanh(self.W(x))
a = F.softmax(self.u(u), dim=1)
x = a.mul(x).sum(1)
return x
class HAN(nn.Module):
def __init__(self):
super(HAN1, self).__init__()
num_embeddings = 5844 + 1
num_classes = 10
num_sentences = 30
num_words = 60
embedding_dim = 200
hidden_size_gru = 50
hidden_size_att = 100
self.num_words = num_words
self.embed = nn.Embedding(num_embeddings, embedding_dim, 0)
self.gru1 = nn.GRU(embedding_dim, hidden_size_gru, bidirectional=True, batch_first=True)
self.att1 = SelfAttention(hidden_size_gru * 2, hidden_size_att)
self.gru2 = nn.GRU(hidden_size_att, hidden_size_gru, bidirectional=True, batch_first=True)
self.att2 = SelfAttention(hidden_size_gru * 2, hidden_size_att)
self.fc = nn.Linear(hidden_size_att, num_classes, True)
def forward(self, x):
x = x.view(x.size(0) * self.num_words, -1).contiguous()
x = self.embed(x)
x, _ = self.gru1(x)
x = self.att1(x)
x = x.view(x.size(0) // self.num_words, self.num_words, -1).contiguous()
x, _ = self.gru2(x)
x = self.att2(x)
x = self.fc(x)
x = F.log_softmax(x, dim=1)
return x
|