写在前面:
如本文描述有错误,希望读到这篇文章的您能够提出批评指正。 联系方式:172310978@qq.com
1.bs4数据分析
一、基础介绍
bs4 全名 BeautifulSoup,是编写 python 爬虫常用库之一,BeautifulSoup4也是一个html/xml的解析器,主要用来解析 html 标签。
-数据解析的原理:
- 1.标签定位
- 2.提取标签、标签属性中存储的数据值
- bs4数据解析的原理:
1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
我们一般在使用bs4库进行数据分析时,最主要使用的都是beautifulsoup。所以我们在使用时一般都是引入这个库
1 | from bs4 import BeautifulSoup |
bs4提供用于数据解析的方法和属性有:
soup.find().text 获取标签内文本内容
soup.get_text() 获取标签内的文本内容
soup.get() 获取标签属性的值
soup.tagName:返回的是文档中第一次出现的tagName对应的标签
soup.find():
-soup.find(‘div’,class_/id/attr=‘song’)
soup.find_all(‘tagName’):返回符合要求的所有标签(列表)
find(‘tagName’):等同于soup.div
有了这些基本介绍下,我们就能够进行基本的bs4数据解析了
接下来将通过几个实例进行巩固。
二、实例操作
1.获取北京新发地网页中每日菜价的所有数据
流程:
分析网页:打开开发者工具,观察我们所需要的内容特点,并且看看网站的源代码中是否由我们所需要的内容,如果有便可以直接进行爬取,如果没有的话可能还需要进行更深入的查找
拿到数据:通过urllib进行request请求,拿到网页数据
数据分析:使用bs4进行解析,拿到我们想要的数据
首先我们需要导入两个库
1 | import requests |
(1).第一步分析网页
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hdGVpuGE-1626970354469)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713153251624.png)]](https://img-blog.csdnimg.cn/ec0e47b2b0c546d58ca10b9756c24a6e.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
我们所需要的东西都在这个表格里,同时我们也发现它还有好多页数据,如果我们想要所有页的数据该怎么办。
我们发现这个网址有一个规律
http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml
当第一页时,list为1,第二页时list为2.依次列推,这样之后我们可以利用这个规律,将所有网页的信息都获取到
右键打开网页源代码,Ctrl+f 查找大白菜
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wGCQAu8w-1626970354470)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713153629269.png)]](https://img-blog.csdnimg.cn/a328b67fc64446c6b69801f6d3b43e36.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
发现我们所需要的数据在源代码中存在。
所以我们直接访问此网址进行数据提取即可
然后打开开发者工具,点击我们要的数据进行观察
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-97azODGT-1626970354472)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713153743053.png)]](https://img-blog.csdnimg.cn/9f43d45a58d54d5a91c4a66418fb7a0c.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
由图也能看到,我们所需要的数据都存在table表中
我们只需要能够定位到table表中,便能进一步得到数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V1RWB49w-1626970354476)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713153849043.png)]](https://img-blog.csdnimg.cn/c00fdea1eab2482b98949e6278cce9c6.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
点开其中的tr我们可以看到,我们所需要的内容都在tr标签的td中,所以我们只需要获取td标签中的文本信息,便完成了整个数据爬取。接下来我们将进入下一步:拿到数据
(2).第二步拿到数据
首先我们定义一个变量,存放网址
1 | url ="http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml" |
当然还需要定义一个变量,存放request请求到的网页信息
同时为了防止可能出现乱码,所以使用encoding转化为”utf-8”
这样其实就已经拿到了我们这个网址的源代码了,我们可以输出看一下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EI6zYXI5-1626970354478)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713154551496.png)]](https://img-blog.csdnimg.cn/6e82a3a584c34eed9b16dd7f8aece4c4.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
下一步便是解析数据了
(3).第三步解析数据
我们使用的是bs4库进行解析
首先 要实例化一个BeautifulSoup对象
1 | page = BeautifulSoup(requ.text,"html.parser") |
设置一个变量存储bs4处理后的源代码数据
beautifulsoup括号中的第一个参数时要解析的HTML文本,第二个参数是使用的解析器,解析HTML使用的是自带的html.parser
根据之前分析网页的过程,我们知道我们需要的内容都存在于一个table表中,所以我们使用bs4中的方法进行数据解析
1 | table = page.find("table", class_="hq_table") |
通过find方法,找到源代码中class=”hq_table”的table内容
我们可以输出看一下得到了什么
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Yct1CpJG-1626970354480)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713155429665.png)]](https://img-blog.csdnimg.cn/876e478b187a4494935b32355ddb2d2c.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
然后下一步我们继续往下找,找到所有的tr标签的内容
1 | trs = table.find_all("tr")[1:] |
找寻所有符合条件的使用find_all方法
因为我们第一行是我们不需要的数据,所以我们从第二行情开始。
同样我们也可以输出结果看看
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dCFXKBah-1626970354481)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713155737006.png)]](https://img-blog.csdnimg.cn/2848037eb5fc4e93a2faa07124492474.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
得到了所有的tr标签后,我们所需要的内容都在其中的td标签中
因为数据是比较多的,所以我们利用一个循环来获取所有的td标签
1 | for tr in trs: |
这样我们就得到了所有的td标签了
也可以输出看一下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t3mnlEtf-1626970354482)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713160209794.png)]](https://img-blog.csdnimg.cn/8513e55b978149a98f787afd51edd121.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
但是我们需要的是td标签中的文本信息
1 | name = tds[0].text #.text 表示拿到被标签标记的内容 |
根据观察我们所获取的内容可以看到,我们的菜品名称是第一个td的文本内容,所以我们输入tds[0],定位到这个标签后加上**.text**,便可以获取被标签标记的文本内容。
输出后便能得到我们最终需要的内容了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C5VsUCyP-1626970354483)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713160716760.png)]](https://img-blog.csdnimg.cn/ab7b173266a449f587d8c6f5799b29bd.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
嘿嘿,这样便完成了
当然我们还可以扩展很多操作,可以将数据进行保存,也可以进行翻页爬取。
2.下载优美图库中的图片,并保存在本地文件中
步骤和上一个例子是一样的,同样还是打开网页,分析网页的内容
(1).第一步分析网页
我们想要下载图片,所以需要拿到图片的下载链接。
首先打开网址,右键查看源代码,看源代码中是否有我们想要的数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3k2gzt0O-1626970354484)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713190718462.png)]](https://img-blog.csdnimg.cn/96653121e32c4bf6a42c86c549373bc5.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
我们看到源代码,发现其实里边存在我们想要的链接。
那便尝试下使用bs4进行提取内容
(2).第二步拿到数据
一样的步骤
导入库:
1 | import requestsfrom bs4 import BeautifulSoup |
然后请求网址,获取网页源代码:
1 | url = "https://www.umei.net/bizhitupian/weimeibizhi/" |
(3).第三步解析数据
实例化bs4对象,并生成page对象
根据网页分析,获得class = “TypeList”下的a标签
1 | page = BeautifulSoup(requ.text,"html.parser") |
得到后,因为我们有很多张图片信息需要获取,所以也用一个循环来进行操作
1 | for a in div: |
然后输出我们需要的图片链接
结果为:
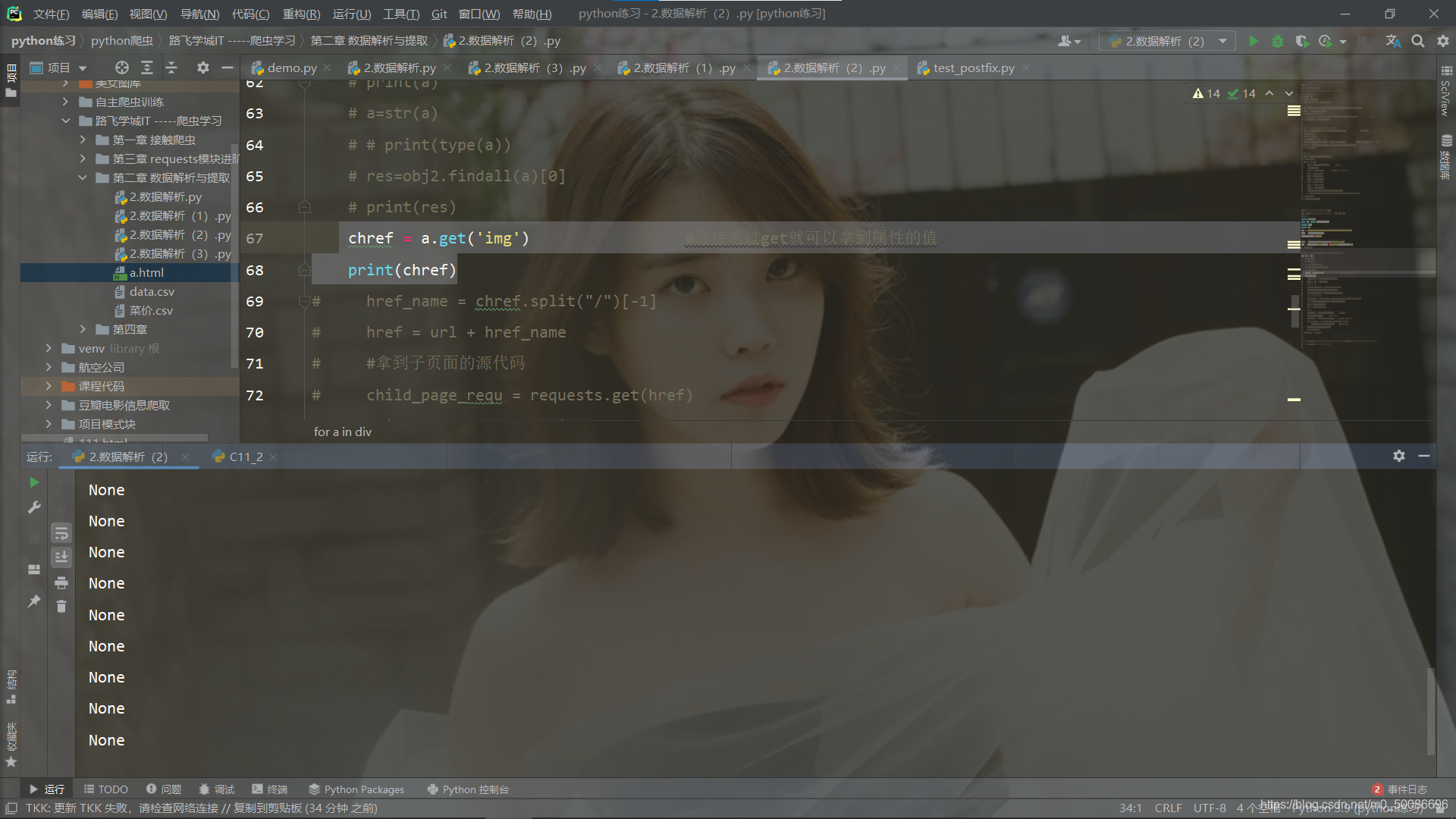
我们所爬取到的却是空值
搞了很久才知道问题所在,因为我们的bs4解析,是根据标签中属性去进行提取其中的值,而img是在a标签里边的内容,我们可以定义href得到网址内容,也可以定义class得到内容,但是无法对标签里的内容进行提取,所以我们使用bs4提取的话,是需要先进入到网站的子网站中去,才能获取到图片的链接。
但是既然在源代码中已经存在了,那我们一样就可以直接提取。我们可以使用正则表达式进行数据提取。
当然这里还是讲解我们的bs4提取方式
因为我们无法直接在源代码中提取到信息,所以我们需要访问到图片的子网页中,下一步便是获得每个子网页的网址,同样因为网址很多,所以我们利用寻循环进行提取
1 | for a in div: |
输出结果便是子网页的网址
但是我们经过观察发现,并不是完整的网址,不能点击进入
我们得到的是:
/bizhitupian/weimeibizhi/225260.htm
/bizhitupian/weimeibizhi/225259.htm
实际网址是:https://www.umei.net/bizhitupian/weimeibizhi/225260.htm
原网址:https://www.umei.net/bizhitupian/weimeibizhi/
经过对比观察我们发现,我们得到的网址其实每个都是只有后边的数字在变化,所以我们可以将后边的数字分开存储。
然后和原网址进行拼接,便能得到所有能够进入的子网页网址
1 | href_name = chref.split("/")[-1]href = url + href_name |
split () :从分号为准,进行切割
我们可以输出一下看看
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-emXe8pdu-1626970354485)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713201942623.png)]
这就是我们得到的内容
当然还没有结束,接下来,我们需要请求子网页的地址,获取子网页的内容,其实和我们获取原网页的内容操作是一样的
1 | child_page_requ = requests.get(href) |
然后也是一样实例化bs4对象,进行数据提取。
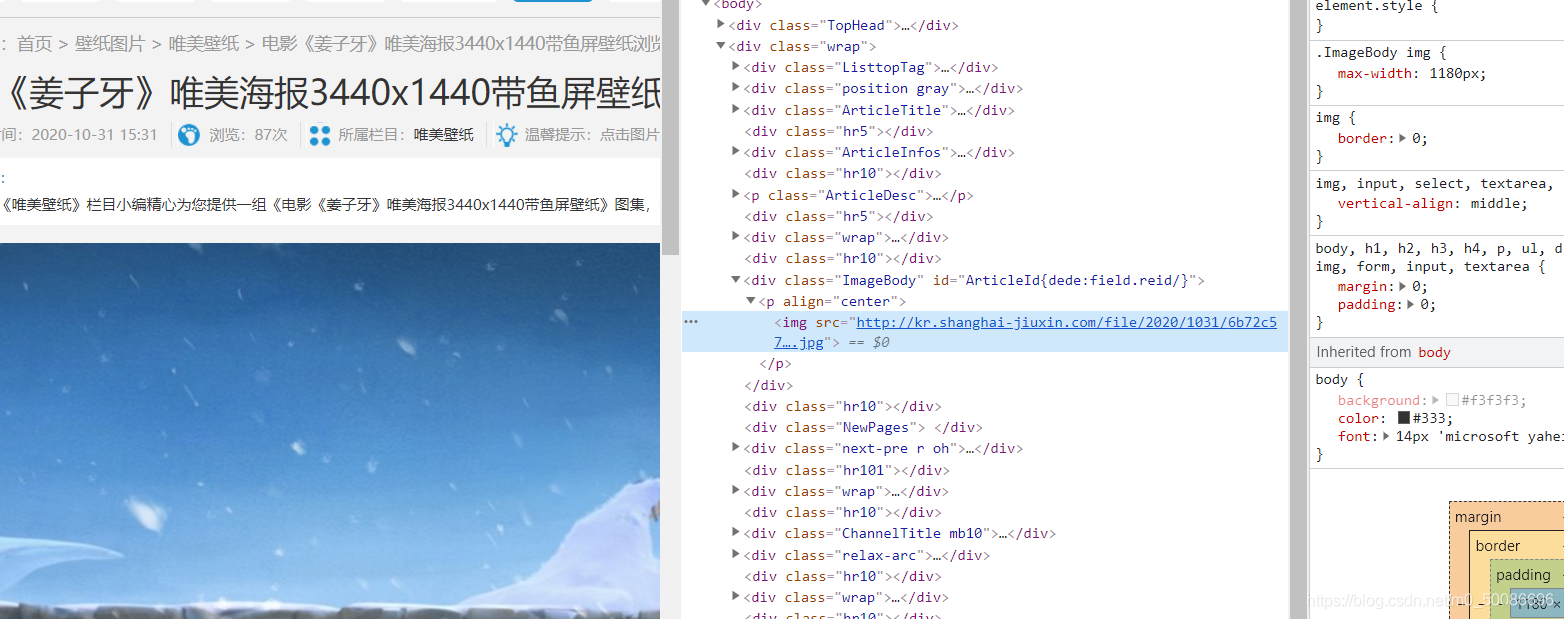
根据网页格式,我们先进入到p标签下,然后在进入到img标签中,最后找到图片链接的属性src,提取到我们需要的图片下载链接。
1 | child_page = BeautifulSoup(child_page_text,"html.parser") |
这样我们就得到了所有的下载链接
当然这个也可以进行翻页爬取,之后可以作为拓展练习操作
补充:正则表达式进行图片链接提取
首先我们也需要引入一个库
1 | import re |
然后定义一个正则表达式规则进行数据提取
1 | obj2 = re.compile(r'img src="(.*?)"',re.S) |
re.compile 编译成 Pattern 对象
然后便可以通过re常用的方法进行匹配查找
1 | for a in div: |
这里我们用了findall进行查找,当然如果我们直接进行查找的话是会报错的,因为我们的正则是在字符串中进行提取数据,但是当时的a是一个bs4对象,所有我们需要先进行转化,才能得到最后的结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H5Tc86Fe-1626970354486)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713200424021.png)]](https://img-blog.csdnimg.cn/f48529792ce74d15aacf8abdf073fe66.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
当然,我们还是回到bs4方法中来,虽然这个网站里存在我们子网页中的信息,但是很多网页中,我们想要的内容都不会在当前网页的源代码中,所以就需要我们去深入查找,我们的bs4也就能够运用进来。
其实我们爬虫的方式有很多种,每个网站的信息也不同,我们可以根据不同的网页信息,去使用不同的爬取方法,只要最终能够得到我们所需要的内容。
注意:我们通过观察源代码中图片和子网页中图片链接对比能发现在源代码中得到的图片只是缩略图,所以如果我们需要对图片清晰度有一定的要求的话,还是得进入到子网页中进行图片下载
(4).第四步保存数据
1 | img_requ = requests.get(src) #请求src链接 |
我们可以执行with open()命令,打开或者新建一个文件夹,并对参数进行设置,建立一个“优美图库”的文件,执行二进制写入的操作
然后将图片写入文件中:
f.write(img_requ.content)
便可以将图片下载到本地文件中了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0zaDNDcc-1626970354487)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713202921177.png)]](https://img-blog.csdnimg.cn/2dd99c04b8a94344aebc5999c343f0a1.png)
因为我们的图库中都是图片,为了不让它在pycharm中占用索引搜索,我们把它标记为已排除文件
因为我们的软件每一次都需要对所有文件进行索引,把文件进行标记后,可以跳过此文件,减少索引时间。
这样,我们这个下载图片的过程就已经完成了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t7fzXK8n-1626970354488)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210713203159435.png)]](https://img-blog.csdnimg.cn/d2c7c905441040a9b00a8aaf6c1de4f0.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)
3.爬取《三国演义》小说
1 | #打开网页源代码检查我们需要的数据 |
简单讲述下爬取过程
首先是打开了网页进行分析,发现当前网页没有我们想要的文本内容,所以我进入到了子网页中查看源代码,找到了我们所需要的内容。所有我们便有了大致的流程,先要从原网址中找到子网址,然后在从子网址中得到数据,进行下载。
所以我们直接请求原网址内容,然后用bs4提取子网页网址。
提取后发现不能直接打开,需要做一些修整,与原网页网址对比后,发现了关系,调整后便可以获取了。
进入子网页后也是一样的请求子网页原代码,然后利用bs4提取文本内容,但是在提取后得到的不仅仅是文本内容,还会得到什么div标签得内容。 但是后面重新提取就没问题了
在发现有问题后我就使用了正则提取,先导入库后,定义了一个正则表达式,然后进行提取,提取内容会发现很多其他符号,利用replace去除后,也能得到想要的内容
文本内容获取到了,但是我还想得到标题,每一个标题对应每一章内容
经过网页分析发现标题并不在子网页中,而是在原网页中,所以我们只需要获取原网页中,a标签中的文本内容便可以了。但是并不知道bs4可以提取文本内容,所以我使用了xpath进行提取。首先导入库from lxml import etree ,并解析HTML文档内容 html = etree.HTML(requ.text)
然后便可以进行xpath提取了,得到a标签的文本内容
后边自己查了一下,原来bs4中可以使用get_text()提取标签中内容。
最后就是将文本存入本地文件中,但是存入后不能自动换行,这是最后一直都没有解决的问题,以及排序的问题,乱序。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-laanEvks-1626970354488)(C:\Users\苏柒\AppData\Roaming\Typora\typora-user-images\image-20210714090857269.png)]](https://img-blog.csdnimg.cn/d3ba198e834847728e7a7193485180ff.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzUwMDg2Njk2,size_16,color_FFFFFF,t_70)