写在前面:
如本文描述有错误,希望读到这篇文章的您能够提出批评指正。 联系方式:172310978@qq.com
参考文章:
- https://zhuanlan.zhihu.com/p/364142487
1. 前言
—
最近在做数据导出的功能,由于要支持批量导出且导出的文件都巨大3GB起,所以决定在导出最终结果时进行压缩
第一天
java压缩,emmm…首先想到的就是java.util.zip下面的各种api,直接上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| /**
* 批量压缩文件 v1.0
*
* @param fileNames 需要压缩的文件名称列表(包含相对路径)
* @param zipOutName 压缩后的文件名称
**/
public static void batchZipFiles(List<String> fileNames, String zipOutName) {
//设置读取数据缓存大小
byte[] buffer = new byte[4096];
ZipOutputStream zipOut = null;
try {
zipOut = new ZipOutputStream(new FileOutputStream(zipOutName));
for (String fileName : fileNames) {
File inputFile = new File(fileName);
if (inputFile.exists()) {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(inputFile));
//将文件写入zip内,即将文件进行打包
zipOut.putNextEntry(new ZipEntry(inputFile.getName()));
//写入文件的方法,同上
int size = 0;
//设置读取数据缓存大小
while ((size = bis.read(buffer)) >= 0) {
zipOut.write(buffer, 0, size);
}
//关闭输入输出流
zipOut.closeEntry();
bis.close();
}
}
} catch (Exception e) {
log.error("batchZipFiles error:sourceFileNames:" + JSONObject.toJSONString(fileNames), e);
} finally {
if (null != zipOut) {
try {
zipOut.close();
} catch (Exception e) {
log.error("batchZipFiles error:sourceFileNames:" + JSONObject.toJSONString(fileNames), e);
}
}
}
}
|
首先利用BufferedInputStream读取文件内容,ZipOutputStream的putNextEntry方法对每一个文件进行压缩写入。
最后将所有压缩后的文件写入到最终的zipOutName文件中。由于用了BufferedInputStream缓冲输入流,文件的读取和写入都是从缓存区(内存)中也就是代码里面对应的byte数组获取,相比较普通的FileInputStream提升了较大的效率。但是不够!耗时如下:
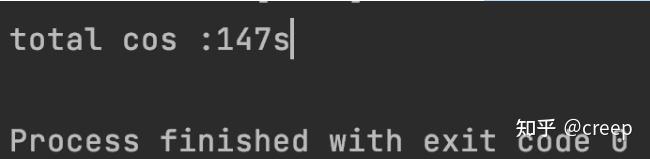
压缩三个大小为3.5GB的文件
第二天
想到了NIO,传统的IO叫BIO(上面代码)是同步阻塞的,读写都在一个线程中。NIO则是同步非阻塞的,核心是channel(通道),buffer(缓冲区),Selector(选择器)。
其实说的通俗易懂点就是NIO在密集型计算下效率之所以比BIO高的原因是NIO是多路复用,用更少的线程最更多的事情,相对于BIO大大减少了线程切换,竞争带来的资源损耗。不多BB了,上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| /**
* 批量压缩文件 v2.0
*
* @param fileNames 需要压缩的文件名称列表(包含相对路径)
* @param zipOutName 压缩后的文件名称
**/
public static void batchZipFiles(List<String> fileNames, String zipOutName) throws Exception {
ZipOutputStream zipOutputStream = null;
WritableByteChannel writableByteChannel = null;
ByteBuffer buffer = ByteBuffer.allocate(2048);
try {
zipOutputStream = new ZipOutputStream(new FileOutputStream(zipOutName));
writableByteChannel = Channels.newChannel(zipOutputStream);
for (String sourceFile : fileNames) {
File source = new File(sourceFile);
zipOutputStream.putNextEntry(new ZipEntry(source.getName()));
FileChannel fileChannel = new FileInputStream(sourceFile).getChannel();
while (fileChannel.read(buffer) != -1) {
//更新缓存区位置
buffer.flip();
while (buffer.hasRemaining()) {
writableByteChannel.write(buffer);
}
buffer.rewind();
}
fileChannel.close();
}
} catch (Exception e) {
log.error("batchZipFiles error fileNames:" + JSONObject.toJSONString(fileNames), e);
} finally {
zipOutputStream.close();
writableByteChannel.close();
buffer.clear();
}
}
|
还是利用java.nio包下面的api,首先用Channels.newChannel()方法将zipOutputStream输出流创建一个写的通道通道,在读取文件内容的时候直接用FileInputStream.getChannel()
获取当前文件读的通道,然后从读的通道中通过ByteBuffer(缓冲区)读取文件内容写入writableByteChannel写通道中,一定记得反转缓冲区buffer.flip(),否则读取的内容就是文件最后的内容byte=0时的。这种方法相较于上面的速度如下图所示:
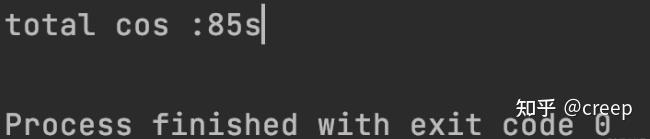
压缩三个大小为3.5GB的文件
第三天
继续优化,听说用上内存映射文件的方式更快!那还等什么,让我来try一try!撸代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| /**
* 批量压缩文件 v3.0
*
* @param fileNames 需要压缩的文件名称列表(包含相对路径)
* @param zipOutName 压缩后的文件名称
**/
public static void batchZipFiles(List<String> fileNames, String zipOutName) {
ZipOutputStream zipOutputStream = null;
WritableByteChannel writableByteChannel = null;
MappedByteBuffer mappedByteBuffer = null;
try {
zipOutputStream = new ZipOutputStream(new FileOutputStream(zipOutName));
writableByteChannel = Channels.newChannel(zipOutputStream);
for (String sourceFile : fileNames) {
File source = new File(sourceFile);
long fileSize = source.length();
zipOutputStream.putNextEntry(new ZipEntry(source.getName()));
int count = (int) Math.ceil((double) fileSize / Integer.MAX_VALUE);
long pre = 0;
long read = Integer.MAX_VALUE;
//由于一次映射的文件大小不能超过2GB,所以分次映射
for (int i = 0; i < count; i++) {
if (fileSize - pre < Integer.MAX_VALUE) {
read = fileSize - pre;
}
mappedByteBuffer = new RandomAccessFile(source, "r").getChannel()
.map(FileChannel.MapMode.READ_ONLY, pre, read);
writableByteChannel.write(mappedByteBuffer);
pre += read;
}
//释放资源
Method m = FileChannelImpl.class.getDeclaredMethod("unmap", MappedByteBuffer.class);
m.setAccessible(true);
m.invoke(FileChannelImpl.class, mappedByteBuffer);
mappedByteBuffer.clear();
}
} catch (Exception e) {
log.error("zipMoreFile error fileNames:" + JSONObject.toJSONString(fileNames), e);
} finally {
try {
if (null != zipOutputStream) {
zipOutputStream.close();
}
if (null != writableByteChannel) {
writableByteChannel.close();
}
if (null != mappedByteBuffer) {
mappedByteBuffer.clear();
}
} catch (Exception e) {
log.error("zipMoreFile error fileNames:" + JSONObject.toJSONString(fileNames), e);
}
}
}
|
这里有两个坑的地方是:
1.利用MappedByteBuffer.map文件时如果文件太大超过了Integer.MAX时(大约是2GB)就会报错:
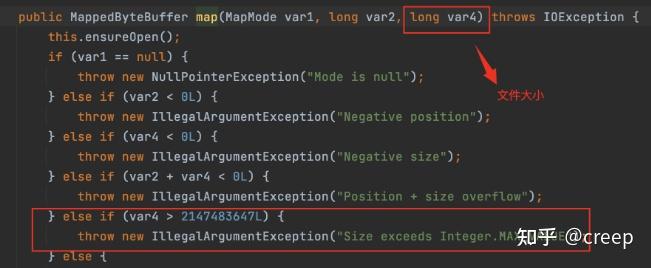
所以这里需要分次将要写入的文件映射为内存文件。
2.这里有个bug,就是将文件映射到内存后,在写完就算clear了mappedByteBuffer,也不会释放内存,这时候就需要手动去释放,详细见上代码。
看速度!
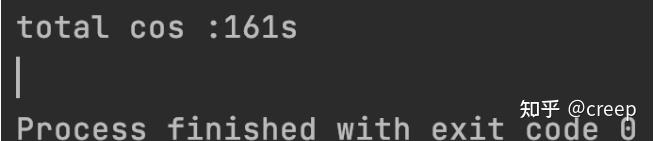
压缩三个大小为3.5GB的文件
肯定是我的打开方式有问题,为什么反而是最慢的。。难道是文件太大了吗?我的机器内存太小了?还是我用的有问题,让我思考一下。。希望留言区讨论一下。
第四天
我在想批量压缩文件这么慢是不是因为是串行的,如果改成多线程并行那不是会快了?说干就干,本来想自己写的,后来在google上查资料发现apache-commons有现成的,那果断不重复造轮子,上代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| /**
* 批量压缩文件 v4.0
*
* @param fileNames 需要压缩的文件名称列表(包含相对路径)
* @param zipOutName 压缩后的文件名称
**/
public static void compressFileList(String zipOutName, List<String> fileNameList) throws IOException, ExecutionException, InterruptedException {
ThreadFactory factory = new ThreadFactoryBuilder().setNameFormat("compressFileList-pool-").build();
ExecutorService executor = new ThreadPoolExecutor(5, 10, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(20), factory);
ParallelScatterZipCreator parallelScatterZipCreator = new ParallelScatterZipCreator(executor);
OutputStream outputStream = new FileOutputStream(zipOutName);
ZipArchiveOutputStream zipArchiveOutputStream = new ZipArchiveOutputStream(outputStream);
zipArchiveOutputStream.setEncoding("UTF-8");
for (String fileName : fileNameList) {
File inFile = new File(fileName);
final InputStreamSupplier inputStreamSupplier = () -> {
try {
return new FileInputStream(inFile);
} catch (FileNotFoundException e) {
e.printStackTrace();
return new NullInputStream(0);
}
};
ZipArchiveEntry zipArchiveEntry = new ZipArchiveEntry(inFile.getName());
zipArchiveEntry.setMethod(ZipArchiveEntry.DEFLATED);
zipArchiveEntry.setSize(inFile.length());
zipArchiveEntry.setUnixMode(UnixStat.FILE_FLAG | 436);
parallelScatterZipCreator.addArchiveEntry(zipArchiveEntry, inputStreamSupplier);
}
parallelScatterZipCreator.writeTo(zipArchiveOutputStream);
zipArchiveOutputStream.close();
outputStream.close();
log.info("ParallelCompressUtil->ParallelCompressUtil-> info:{}", JSONObject.toJSONString(parallelScatterZipCreator.getStatisticsMessage()));
}
|
先看结果:
压缩三个大小为3.5GB的文件
果然还是并行的快!
原文作者:tinyOrange
原文地址:https://juejin.cn/post/6949355730814107661